A beginner’s guide to modern natural language processing
We built a clickbait classifier with three different NLP models. The simplest method surprisingly beat the more complex neural network. Here’s why.
#1about 5 minutes
Understanding the core challenge of natural language processing
Machine learning models require numerical inputs, so raw text must be converted into a numerical format called a vector or text embedding.
#2about 6 minutes
Exploring bag-of-words methods for text vectorization
Binary and count vectorization create features based on the presence or frequency of words in a document, ignoring their original context.
#3about 4 minutes
How Word2Vec captures word meaning in vector space
The Word2Vec model learns numerical representations for words by analyzing their surrounding context, grouping similar words closer together in a multi-dimensional space.
#4about 5 minutes
Training a Word2Vec model in Python using Gensim
A practical demonstration shows how to clean text data and train a custom Word2Vec model to generate embeddings for a specific vocabulary.
#5about 3 minutes
Creating document embeddings by averaging word vectors
A simple yet effective method to represent an entire document is to retrieve the embedding for each word and calculate their average vector.
#6about 2 minutes
Evaluating the performance of the Word2Vec classifier
The classifier trained on averaged word embeddings achieves 95% accuracy, with errors often occurring on headlines with misleading topics or tones.
#7about 3 minutes
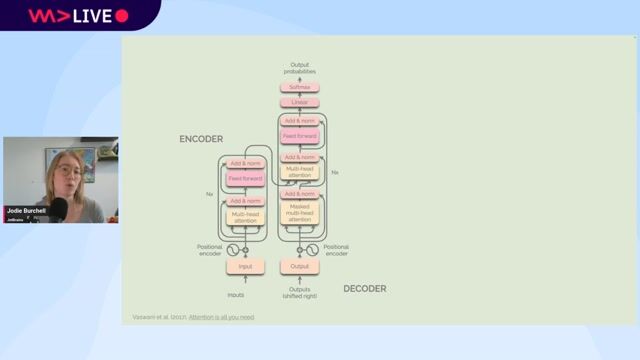
Overcoming context limitations with transformer models
Transformer models use a self-attention mechanism to weigh the importance of other words in a sentence, allowing them to understand a word's meaning in its specific context.
#8about 5 minutes
Understanding how the BERT model is pre-trained
BERT learns a deep understanding of language by being pre-trained on tasks like predicting masked words and determining correct sentence order, enabling it to be fine-tuned for specific applications.
#9about 7 minutes
Fine-tuning a BERT model with the Transformers library
Using the Hugging Face Transformers library, a pre-trained DistilBERT model is fine-tuned for the clickbait classification task, requiring specific tokenization with attention masks.
#10about 2 minutes
Choosing the right text processing model for your task
While the fine-tuned BERT model achieves the highest accuracy at 99%, simpler methods like count vectorization can outperform Word2Vec and may be sufficient depending on the use case.
#11about 2 minutes
Using word embeddings to improve downstream NLP tasks
Word embeddings can be combined with other techniques, such as TF-IDF weighting, to extract more signal and improve performance on tasks like sentiment analysis.
#12about 2 minutes
Addressing overfitting and feature leakage in production
Preventing overfitting involves using validation sets, ensuring representative data samples, and checking for feature leakage where a feature inadvertently reveals the outcome.
#13about 2 minutes
Handling out-of-vocabulary and rare terms in NLP
For rare or out-of-vocabulary terms that models struggle with, symbolic rule-based approaches can be used as a complementary system to handle important edge cases.
#14about 3 minutes
Advice for starting a career in data science
Aspiring data scientists should focus on gaining hands-on experience with real-world datasets and building a portfolio of projects to develop an intuition for common issues.
Related jobs
Jobs that call for the skills explored in this talk.
Matching moments
03:01 MIN
The evolution of NLP from early models to modern LLMs
Harry Potter and the Elastic Semantic Search
07:44 MIN
Defining key GenAI concepts like GPT and LLMs
Enter the Brave New World of GenAI with Vector Search
08:25 MIN
From Word2Vec and LSTMs to modern transformers
What do language models really learn
02:00 MIN
Understanding the fundamentals of generative AI for developers
Java Meets AI: Empowering Spring Developers to Build Intelligent Apps
03:42 MIN
Using large language models as a learning tool
Google Gemini: Open Source and Deep Thinking Models - Sam Witteveen
03:30 MIN
Using large language models for voice-driven development
Speak, Code, Deploy: Transforming Developer Experience with Voice Commands
03:23 MIN
The evolution of large language models like GPT
MLOps and AI Driven Development
01:54 MIN
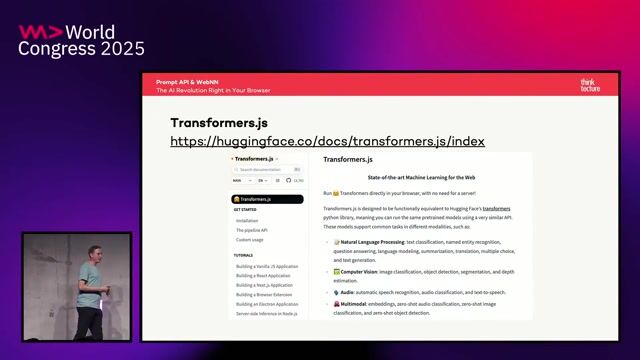
Exploring diverse ML workloads with Transformers.js
Prompt API & WebNN: The AI Revolution Right in Your Browser
What Are Large Language Models?Developers and writers can finally agree on one thing: Large Language Models, the subset of AIs that drive ChatGPT and its competitors, are stunning tech creations. Developers enjoying the likes of GitHub Copilot know the feeling: this new kind of te...
Adrien Book
Top 5 ChatGPT Plugins for DevelopersThe last few weeks have been very interesting in the AI space. We saw the release of a new updated version of ChatGPT from GPT-3.5 to GPT-4. Within a couple of days, Google soft-launched their competitor AI chatbot, Bard (available in the US and UK)....
Eli McGarvie
16 Ways Developers Can Use ChatGPT-4 and GPT-4oChatGPT has been busy getting new designations. If you’ve been scrolling on 𝕏 over the last week, then you’ve seen the ChatGPT-4o announcement and probably thought of Joaquin Phoenix’s virtual girlfriend on Her.Beyond the references to flicks, the la...
Eli McGarvie
13 NEW AI Tools That Use ChatGPT 🤯Our dear friend Bill Gates has recently suggested that the ChatGPT revolution is as big as the invention of mobile phones and the internet. So we thought it would be interesting to put together a list of all the useful applications that are powered b...
From learning to earning
Jobs that call for the skills explored in this talk.










.png?w=240&auto=compress,format)




