#1about 2 minutes
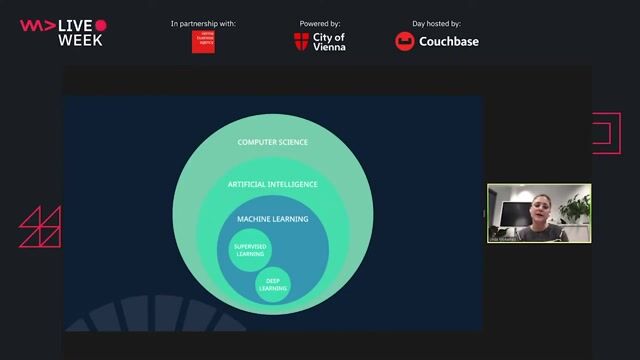
Understanding the main paradigms of machine learning
Learn the distinctions between supervised, unsupervised, semi-supervised, and reinforcement learning based on data and goals.
#2about 1 minute
Differentiating between regression and classification tasks
Supervised learning is broken down into predicting continuous variables with regression and discrete labels with classification.
#3about 3 minutes
Why data preparation is a critical first step
The principle of 'garbage in, garbage out' highlights the need to analyze and clean data before training any model.
#4about 2 minutes
Converting categorical data into numerical features
Transform non-numerical string data into a machine-readable format using label, ordinal, and one-hot encoding techniques.
#5about 2 minutes
Standardizing numerical data with scaling techniques
Handle large or small numerical values that can negatively impact training by applying scaling methods like min-max or Z-score normalization.
#6about 2 minutes
Choosing a strategy for handling missing data
Address missing values in a dataset by either deleting the affected rows/columns or using imputation to replace them.
#7about 3 minutes
Analyzing a dataset for potential bias and imbalance
A practical example using the adult census dataset demonstrates how to identify and understand biases related to age, sex, and race.
#8about 5 minutes
Splitting data for model training and evaluation
Properly divide your dataset into training and testing sets using strategies like holdout, cross-validation, and stratification to avoid data leakage.
#9about 2 minutes
Using metrics to evaluate model performance
Measure classification model success with accuracy, precision, and F1 score, and regression model success with mean absolute or squared error.
#10about 3 minutes
Understanding overfitting and the bias-variance tradeoff
Find the optimal model complexity by balancing the training error and test error to avoid underfitting or overfitting.
#11about 3 minutes
Tuning hyperparameters and selecting the right algorithm
Optimize model performance by searching for the best parameters with grid search or randomized search, and explore meta-learning for algorithm selection.
#12about 3 minutes
Introduction to decision trees and random forests
Decision trees offer a transparent, white-box model, but random forests typically provide better performance by combining multiple trees.
#13about 7 minutes
Code demo: Preprocessing and training a classifier
A step-by-step Python example shows how to preprocess data, handle missing values, and train decision tree and random forest classifiers using scikit-learn.
#14about 4 minutes
Fundamentals of neural networks and perceptrons
Explore the basic building block of neural networks, the perceptron, and see how they are combined into multi-layer perceptron (MLP) architectures.
#15about 2 minutes
Overview of deep neural networks and architectures
Go beyond simple MLPs to understand deep neural networks and specialized architectures like CNNs for images and RNNs for language.
#16about 2 minutes
Common pitfalls and solutions for neural networks
Address common issues like overfitting with techniques such as dropout and regularization, and tackle the black box problem with model explainers.
#17about 2 minutes
Q&A: Scaling machine learning for large datasets
Handle large datasets by using parallelization to train smaller models simultaneously or by leveraging pre-trained components with transfer learning.
#18about 3 minutes
Q&A: Using scikit-learn for model evaluation
Effectively compare models in scikit-learn by using the built-in metrics module and visualizing results with tools like confusion matrices.
#19about 2 minutes
Q&A: Handling imbalanced datasets during training
Correct for imbalanced target labels in a classification problem by applying oversampling to duplicate instances of the minority class.
#20about 2 minutes
Q&A: Advantages of scikit-learn over other libraries
Scikit-learn is ideal for beginners due to its ease of use and wide variety of algorithms, though specialized libraries offer deeper customization.
#21about 2 minutes
Q&A: Identifying red flags in datasets
Watch for red flags like poor quality data, excessive missing values, and sensitive information that can compromise model performance and ethics.














.gif?w=240&auto=compress,format)



