How do you fit a 400MB NLP model into a 250MB serverless function? Learn the model distillation and dependency tricks that make it possible.
#1about 9 minutes
Exploring practical NLP applications at Slido
Several NLP-powered features are used to enhance user experience, including keyphrase extraction, sentiment analysis, and similar question detection.
#2about 4 minutes
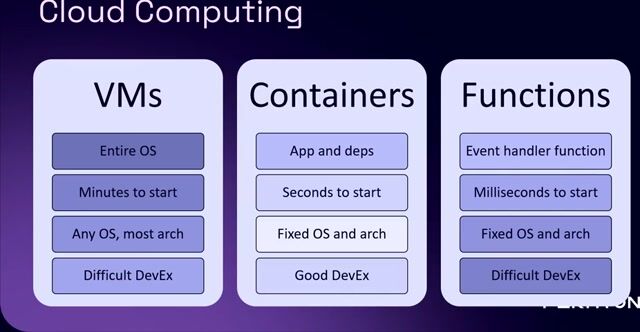
Choosing serverless for ML model deployment
Serverless was chosen for its ease of deployment and minimal maintenance, but it introduces challenges like cold starts and strict package size limits.
#3about 8 minutes
Shrinking large BERT models for sentiment analysis
Knowledge distillation is used to train smaller, faster models like TinyBERT from a large, fine-tuned BERT base model without significant performance loss.
#4about 8 minutes
Building an efficient similar question detection model
Sentence-BERT (SBERT) provides an efficient alternative to standard BERT for semantic similarity, and knowledge distillation helps create smaller, deployable versions.
#5about 3 minutes
Using ONNX Runtime for lightweight model inference
The large PyTorch library is replaced with the much smaller ONNX Runtime to fit the model and its dependencies within AWS Lambda's package size limits.
#6about 3 minutes
Analyzing serverless ML performance and cost-effectiveness
Increasing allocated RAM for a Lambda function improves inference speed, potentially making serverless more cost-effective than a dedicated server for uneven workloads.
#7about 3 minutes
Key takeaways for deploying NLP models serverlessly
Successful serverless deployment of large NLP models requires aggressive model size reduction, lightweight inference libraries, and an understanding of the platform's limitations.
Related jobs
Jobs that call for the skills explored in this talk.
Matching moments
03:15 MIN
Delivering customizations via decoupled ML models
Building the platform for providing ML predictions based on real-time player activity
25:09 MIN
Audience Q&A on serverless IoT development
Building your way to a serverless powered IOT Buzzwire game
05:17 MIN
Q&A on monoliths, serverless, and specific use cases
Why you shouldn’t build a microservice architecture
03:31 MIN
Project learnings and future development opportunities
Leverage Cloud Computing Benefits with Serverless Multi-Cloud ML
03:55 MIN
Exploring central server and edge deployment options
DevOps for Machine Learning
12:42 MIN
Running large language models locally with Web LLM
Generative AI power on the web: making web apps smarter with WebGPU and WebNN
01:24 MIN
The benefits and use cases for small models
distil labs – small model training, made simple
04:41 MIN
Identifying the key challenges of serverless functions
Fun with PaaS – How to use Cloud Foundry and its uniqueness in creative ways
MLops – Deploying, Maintaining And Evolving Machine Learning Models in ProductionWelcome to this issue of the WeAreDevelopers Live Talk series. This article recaps an interesting talk by Bas Geerdink who gave advice on MLOps.About the speaker:Bas is a programmer, scientist, and IT manager. At ING, he is responsible for the Fast...
Benedikt Bischof
MLOps – What’s the deal behind it?Welcome to this issue of the WeAreDevelopers Live Talk series. This article recaps an interesting talk by Nico Axtmann who introduced us to MLOpsAbout the speaker:Nico Axtmann is a seasoned machine learning veteran. Starting back in 2014 he observed ...
Luis Minvielle
What Are Large Language Models?Developers and writers can finally agree on one thing: Large Language Models, the subset of AIs that drive ChatGPT and its competitors, are stunning tech creations. Developers enjoying the likes of GitHub Copilot know the feeling: this new kind of te...












.gif?w=240&auto=compress,format)
.gif?w=240&auto=compress,format)
.png?w=240&auto=compress,format)

