Don't Change the Partition Count for Kafka Topics!
A well-intentioned infrastructure change silently corrupted our search index. Discover how increasing a Kafka topic's partition count can break your entire data pipeline.
#1about 5 minutes
An overview of the data indexing pipeline architecture
The system moves data from a MySQL primary data store to an Elasticsearch search server using a Kafka and Kafka Connect pipeline.
#2about 1 minute
Using Kafka partition offset for optimistic concurrency control
The system leverages the Kafka partition offset as the document version number in Elasticsearch to enable parallel indexing without data consistency issues.
#3about 2 minutes
Investigating a mysterious data deletion failure in production
A bug report about Elasticsearch failing to delete documents, which serves stale data, could not be reproduced in local or testing environments.
#4about 5 minutes
Discovering the offset and version number mismatch
Manual inspection reveals that the document version in Elasticsearch is significantly higher than the new message offset in the Kafka topic for the same key.
#5about 4 minutes
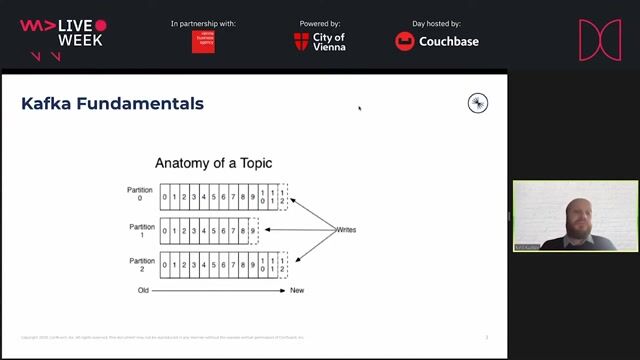
How changing partition count breaks message ordering guarantees
Increasing the Kafka topic's partition count changes the key hashing algorithm, causing new messages for the same key to land in different partitions with lower offsets.
#6about 4 minutes
The solution and key lessons for managing Kafka topics
The fix required a full data re-ingestion into a new Kafka topic, highlighting the lesson to never increase partition count when message ordering is critical.
Related jobs
Jobs that call for the skills explored in this talk.
Matching moments
01:45 MIN
Exploring Kafka's core concepts of events, topics, and partitions
Let's Get Started With Apache Kafka® for Python Developers
01:17 MIN
Recapping Kafka's capabilities for real-time data feeds
Let's Get Started With Apache Kafka® for Python Developers
03:30 MIN
Navigating the Kafka ecosystem and the power of community
Let's Get Started With Apache Kafka® for Python Developers
22:41 MIN
Answering questions on Kafka use cases, careers, and learning
Let's Get Started With Apache Kafka® for Python Developers
05:28 MIN
Common challenges of running Kafka at scale
Tips, Techniques, and Common Pitfalls Debugging Kafka
04:23 MIN
A traditional approach to streaming with Kafka and Debezium
Python-Based Data Streaming Pipelines Within Minutes
03:41 MIN
Decoupling microservices with event streams
From event streaming to event sourcing 101
01:34 MIN
Managing data consistency with change data capture
Software Engineering Social Connection: Yubo’s lean approach to scaling an 80M-user infrastructure
Dev Digest 134 - Where pixels sing?News and ArticlesWeAreDevelopers LIVE Data and Security Day is on Wednesday, 25/09/2024. Learn about OPC UA Updates, Best Practices for Using GitHub Secrets, Passwordless Web 1.5, Emerging AI Security Risks, Data Privacy in LLMs and get a chance to t...
Chris Heilmann
Dev Digest 109 -Egg-citing things…As we are heading into the Easter break, here are some things to spend some time on. There's resources on improving the performance of your code and you hear from the winners of CODE100 Amsterdam what it was like to be on stage. Also, hang tight as t...
Chris Heilmann
WeAreDevelopers LIVE days are changing - get ready to take partStarting with this week's Web Dev Day edition of WeAreDevelopers LIVE Days, we changed the the way we run these online conferences. The main differences are:Shorter talks (half an hour tops)More interaction in Q&AA tips and tricks "Did you know" sect...
Chris Heilmann
Dev Digest 138 - Are you secure about this?Hello there! This is the 2nd "out of the can" edition of 3 as I am on vacation in Greece eating lovely things on the beach. So, fewer news, but lots of great resources. Many around the topic of security. Enjoy! News and ArticlesGoogle Pixel phones t...
From learning to earning
Jobs that call for the skills explored in this talk.