What if you treated every incident like a compressed agile sprint? Learn how this approach helps you resolve outages faster and minimize customer impact.
#1about 6 minutes
Defining digital service incidents and key stakeholders
An incident is any interruption to a digital service, from a full outage to an SLO breach, involving service teams, IT, support, and management.
#2about 4 minutes
Applying agile and SRE principles to incident response
Improve incident management by adopting agile principles like iterative mitigation, DevOps culture-bridging, Scrum retrospectives, and SRE-driven automation.
#3about 3 minutes
Using Failure Friday to practice incident management
Regularly practicing incident response through simulated outages, known as Failure Friday, builds team confidence and refines resolution processes.
#4about 2 minutes
Demo setup of a company's modern and legacy toolchains
The demo scenario involves a company with an agile team using tools like Slack and Jira, and a major incident team using ServiceNow.
#5about 5 minutes
Demo of receiving an alert and initiating an incident
An automated workflow enriches an incoming alert with diagnostic data and, upon escalation, creates linked artifacts in Slack, Jira, and ServiceNow.
#6about 6 minutes
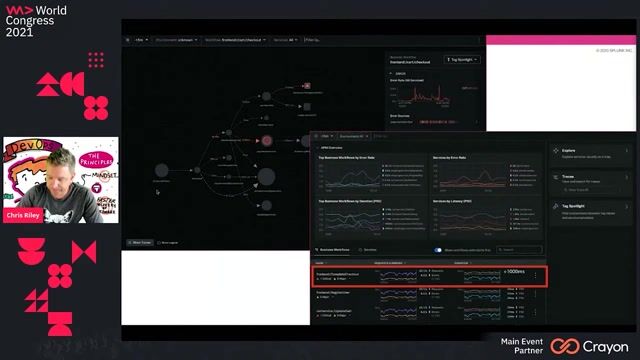
Using an incident console to manage response and resolvers
The incident console provides a central hub for tracking status, managing on-call resolvers, and accessing collaboration channels to streamline remediation.
#7about 2 minutes
Conducting a post-incident review to drive improvement
After resolution, a post-incident review helps analyze the timeline, document learnings, and create trackable action items to prevent future occurrences.
#8about 9 minutes
Building custom automation with a low-code flow designer
The low-code flow designer allows teams to build custom automation workflows by connecting triggers and steps to integrate with any tool, including on-premise systems.
Related jobs
Jobs that call for the skills explored in this talk.
Matching moments
05:39 MIN
Q&A on agile development, tooling, and observability
Why shifting left is so important for software developers
01:12 MIN
Improving incident response to make on-call less painful
What Developers Get Wrong About Application Quality
01:56 MIN
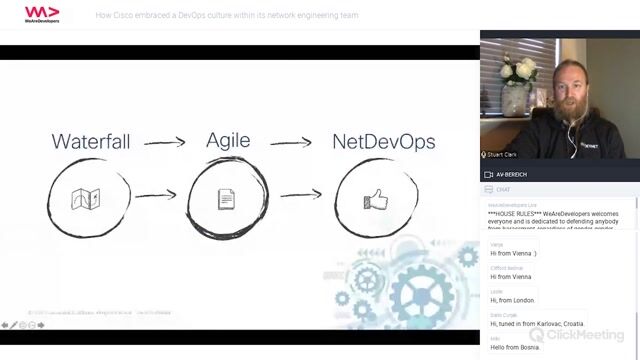
Shifting from a waterfall to an agile NetDevOps workflow
How Cisco embraced a DevOps culture within its network engineering team
09:21 MIN
Navigating the common pitfalls of DevOps adoption
Demystifying DevOps—Pros, cons, dos & don'ts
03:13 MIN
Applying an agile mindset to an infrastructure project
AWS Migration within 3 months
04:03 MIN
Why agile teams struggle with adopting new technologies
Retooling and refactoring - an investment in people.
01:18 MIN
Making time for transformation amid constant firefighting
How Cisco embraced a DevOps culture within its network engineering team
04:41 MIN
Actionable takeaways for SREs on incident management
Serverless Observability: where SLOs meet transforms
WeAreDevelopers LIVE days are changing - get ready to take partStarting with this week's Web Dev Day edition of WeAreDevelopers LIVE Days, we changed the the way we run these online conferences. The main differences are:Shorter talks (half an hour tops)More interaction in Q&AA tips and tricks "Did you know" sect...
Eli McGarvie
Stop Wasting Time: How to Lead a Stand-Up Meeting & Get ResultsWe all know the feeling: your stand-up meeting starts… and the energy in the room slowly deflates. Eyes glaze over, minds wander. Maybe you can even see their attention drop on smartphones or laptops.Within minutes or even seconds, instead of a quick...
Dev Digest 134 - Where pixels sing?News and ArticlesWeAreDevelopers LIVE Data and Security Day is on Wednesday, 25/09/2024. Learn about OPC UA Updates, Best Practices for Using GitHub Secrets, Passwordless Web 1.5, Emerging AI Security Risks, Data Privacy in LLMs and get a chance to t...
From learning to earning
Jobs that call for the skills explored in this talk.












.webp?w=240&auto=compress,format)





